
Содержание:
Webarchive – история всего интернета на одном сайте
Практическое использование веб-архива
Восстановление сайта без «бэкапа» и поиск нужного архива
Уникальный контент из «мертвых» сайтов
Сайт web.archive.org имеет за собой большую и почти невыполнимую миссию – сохранить всю историю интернета. Причем информация в архиве выглядит как стандартная веб-страница. Данный ресурс может сохранить большое количество копий одного сайта за все время его существования. Так что по амбициям этот ресурс не уступает знаменитой Википедии.
В первую очередь данный архив интернета полезен тем, кто по каким-либо причинам не сделал копию собственного ресурса. В таком случае при непредвиденных обстоятельствах сохранится возможность восстановить свой сайт только с помощью веб-архива. Для этого необходимо будет отменить все ссылки от привязки к веб-архиву и сделать их прямыми для вашего сайта.
Также web.archive.org может быть полезен тем, кто ищет некий уникальный контент. Поскольку за время существования интернета «умерло» великое множество разнообразных страниц, на просторах архива можно будет отыскать действительно полезную информацию, которая с легкостью сможет пройти проверку на уникальность. Основная проблема заключается в том, что отыскать нужный контент в огромных «дебрях» archive.org довольно трудно. Необходимо четко представлять, что и где искать.
Очевидно, что через веб архив сайтов возможно пройти по «мертвым» ссылкам, даже если они уже исчезли из кеша Гугла или Яндекса.
Ну и для любителей поностальгировать существует возможность узнать, как менялась история любого сайта, который существовал за время работы web.archive.org. Ведь archive.org – это своеобразная «машина времени», в которой доступна история всего интернета. Своеобразный взгляд в прошлое.
Данный сервис начал свое существование в 1996 году. Но, что интересно, сам себя archive.org внес в базу лишь в последующем году.
Так выглядела стартовая страница ресурса в то время

Архив использует невероятный объем памяти (больше тысячи терабайт), включая аудио- и видеофайлы, а также страницы отсканированных книг. Можно отыскать не только веб-страницы ресурсов (которых уже насчитывается больше ста миллиардов), но и просмотреть телепередачи, которых уже давно нет в эфире. Такая функция называется «Waybackmachine»

Фактически попасть в базу данных этого ресурса очень просто. Сайт не должен содержать в своем файле robot.txt запрет на его индексацию роботом архива. Чаще всего такой запрет отображается так:
User-agent: ia_archiver
Disallow: /
Также некоторые сайты archive.org может попросту не найти, поскольку они отсутствуют в базах данных. Чтобы повысить вероятность попадания в них, ссылки на ваш сайт должны быть размещены на других ресурсах, которые уже есть в базе данных архива.
Веб архив не учитывает прямые изменения на сайте, поскольку он делает слепки любого ресурса беря за основу собственные таймеры и алгоритмы. Именно поэтому использовать сервис как доступ к временно неработающим ссылкам бесполезно. Тем более, что как Google, так и Yandex предоставляет возможность просмотра сохраненной копии из кеша.
Данный сервис представляет ценность именно для тех людей, которые хотят посмотреть уже несуществующую страницу.
По архивам можно перемещаться с помощью календарного меню вверху страницы. Синим кружком помечены даты, когда сделаны слепки. Нажав на него, можно увидеть точное время создания слепка и их количество в заданный день. Эта делается во избежание потери информации, поскольку данные в хранилищах со временем могут испортиться, а также отдельные копии могут быть битыми.
Нажав на просмотр любого слепка, вы перейдете на полностью рабочую страницу ресурса. То есть, все внутренние ссылки будут работать. Однако, сервис может неидеально воспроизвести оформление, а также могут исчезнуть некоторые элементы меню. Паниковать не стоит, поскольку код страницы идентичен вашему. Но простым копированием кода восстановить утерянную информацию не удастся. Поскольку веб хранилище само генерирует ссылки внутри каждого слепка, иначе вы бы перешли на актуальную версию, а не на историю сайта.
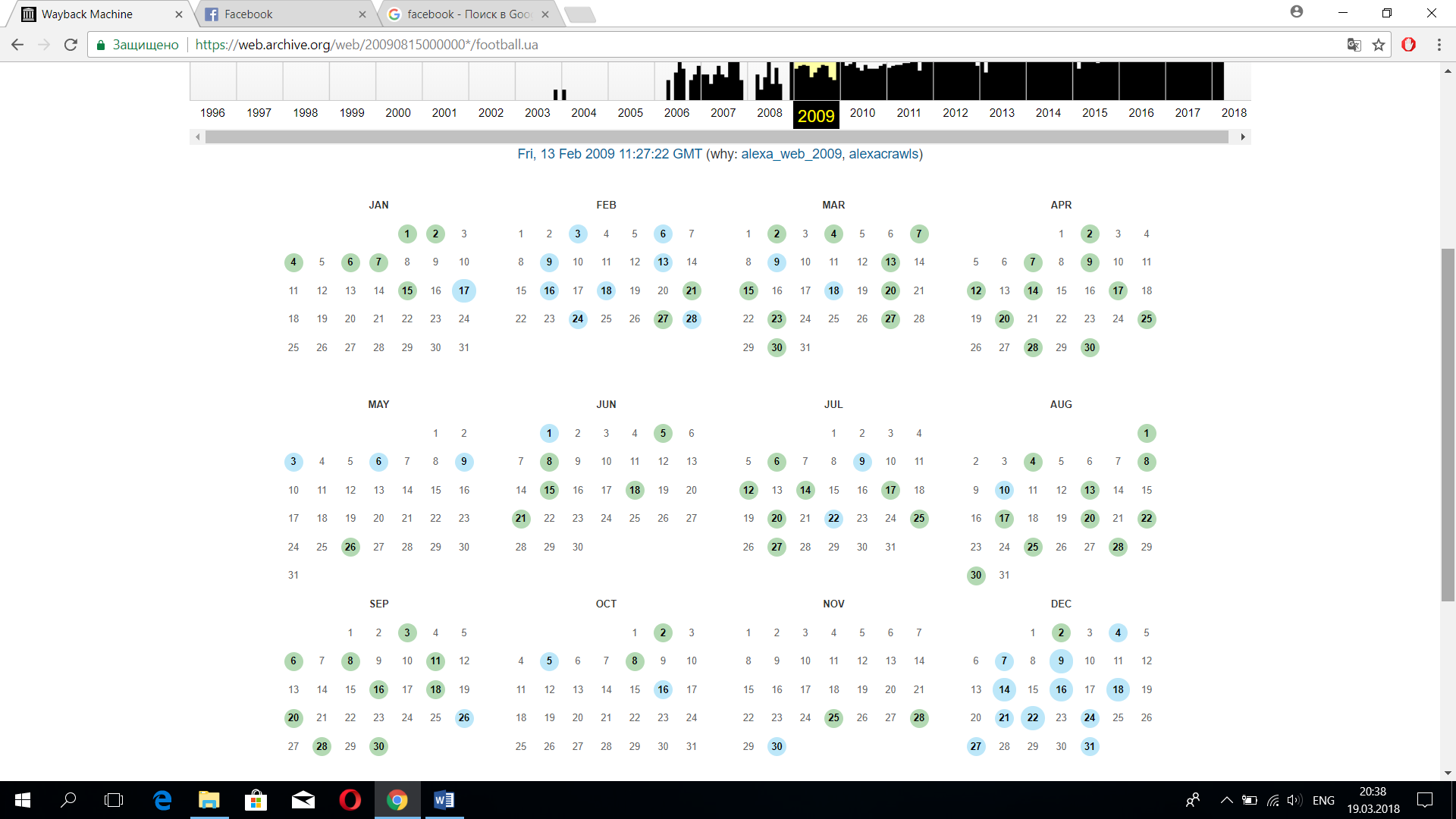
Чтобы заставить все работать, нужно удалить вступительную часть ссылки. Однако, во избежание рутинной работы сервис имеет инструмент замены внутренних ссылок на оригинальные. Чтобы воспользоваться им, нужно скопировать веб-адрес страницы с нужным слепком и в конце даты добавить конструкцию «id_».
Адрес должен иметь такой вид
https://web.archive.org/web/20090206215515/http://football.ua:80/
Вставляем конструкцию «id_»
https://web.archive.org/web/20090206215515id_/http://football.ua:80/
Далее возвращаем веб-адрес в строку и нажимаем Enter. Очевидно, что восстановление ресурса таким образом займет просто невероятное количество времени. Но когда выхода нет – выбирать не приходится. Чтобы никогда не пользоваться таким неудобным способом восстановления – лучше делайте бэкапы своего сайта по несколько раз в день. Это поможет уберечь ваши нервы от лишнего стресса.
Если вам нужно отобразить все страницы необходимого сайта, введите такой веб-адрес в строку браузера:
https://web.archive.org/web/*/football.ua
На странице, которая открылась, существует возможность отфильтровать файлы по разным форматам.
Каждый день из интернета исчезают десятки и даже сотни разнообразных сайтов. Стоит отметить, что абсолютное большинство не представляет особой ценности, но в каждой реке можно найти много крупинок золота. Главное, чтобы полезные сайты имели хотя бы один работающий слепок в archive.org.
Поскольку информация из умерших сайтов поступенно перестает индексироваться поисковыми системами, такой контент становится уникальным (конечно, если он не был «сплагиачен» до этого). Выставив эту информацию на свой ресурс, вы станете ее правообладателем или первоисточником для поисковых систем. Главное, предварительно проверить ее на уникальность, чтобы не нарушить ничей копирайт. Но как именно отыскать подобные ресурсы среди гор мусора?
К счастью, существует один способ.
С помощью регистратора домена nic.ru можно получить список доменов, которые освободились или освободятся в скором времени. В таком списке можно увидеть количество архивов в Archive.org для каждого исчезнувшего домена, однако проверить наличие домена можно и в нескольких онлайн-сервисах. Например, в этом, http://www.seogadget.ru/wa или этом http://r-tools.org/page/tools/webarchive_checker.
Проверить наличие домена иностранного веб-адреса можно, скачав файл по ссылке: http://www.pool.com/Downloads/PoolDeletingDomainsList.zip
После этого нужно всего лишь просматривать информацию Webarchive с каждого ресурса, который вас заинтересовал. Безусловно, такой метод предполагает наличие внимательности, а также терпения, поскольку качество большинства данного контента будет низкопробным.
Как видим, ресурс Archive.org имеет не только практическую пользу, в виде поиска уникального контента и последующей возможности восстановить собственную страницу. Для некоторых людей этот сервис – шанс узнать, как выглядел интернет раньше. Отыскать и зайти на любимый сайт детства проще простого с помощью данного сервиса. Archive.org может показать совершенно новый и незнакомый мир.
Оставьте ваш e-mail, чтобы получать подборки наших новостей.
